
Incident Postmortem: November 16th, 2020
by Drew Rothstein, Director of Engineering

On November 16th, Coinbase experienced an outage that impacted both our web and mobile applications. We quickly suspected the root cause was based on an ongoing migration and started to remediate the issue. This post provides some more detail about what occurred.
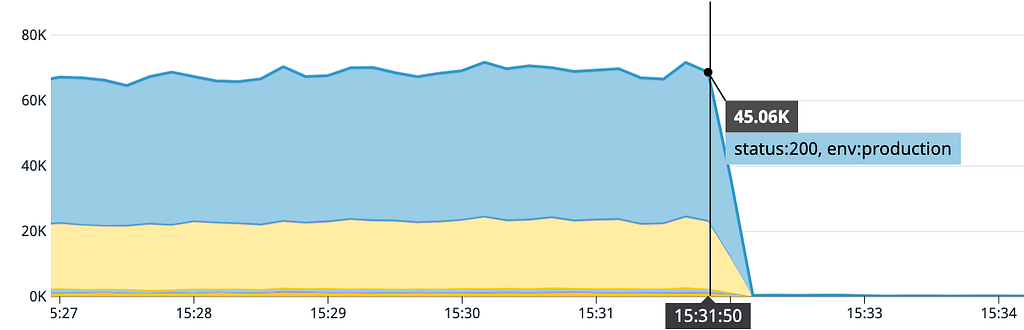
Around 3:32pm EST we started to see multiple service graphs similar to the above with a stark drop-off in traffic towards zero. Our first pages started to roll in over the next few minutes. By 3:38pm EST our incident process had kicked in with initial impact, severity, and our automated document, video conferencing and status page updates.
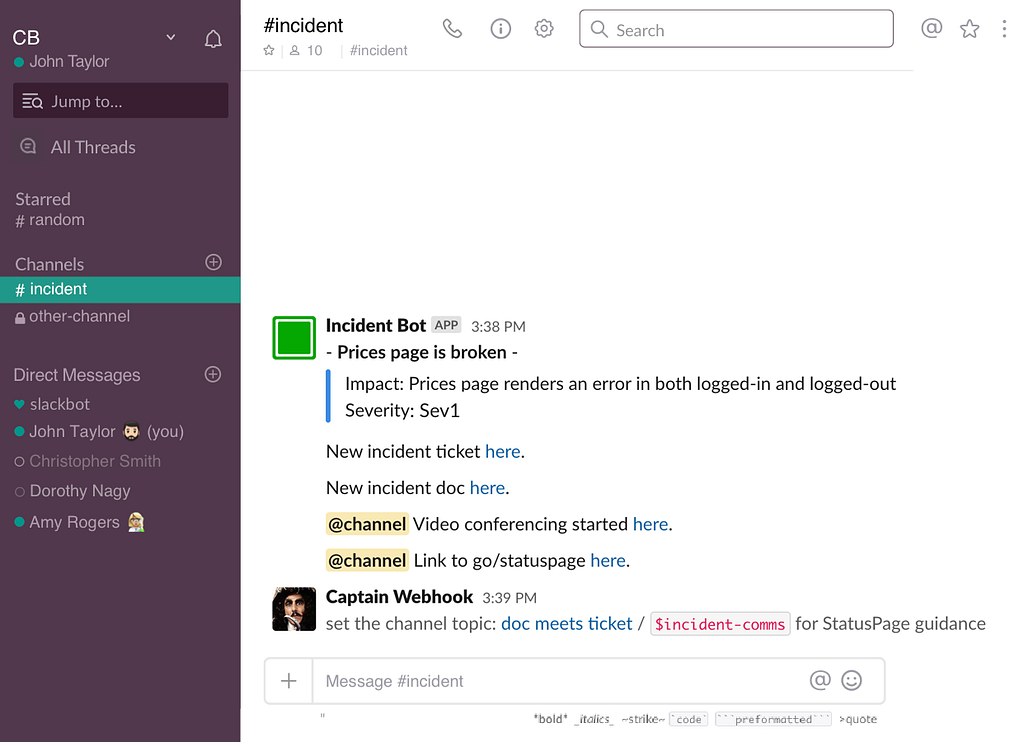
Within three minutes of incident creation we suspected that this was related to a migration that we were running to update internal TLS certificates between services. We require validation of TLS certificates between services and were in the process of updating them for an upcoming expiration.
Given our suspicion about the TLS certificate migration, we started to prepare to rollback the most important and critical services. As we had split this migration up into many pieces it required many pull requests (PRs) to revert, and these were prepared, shipped, and automatically applied once we determined it was safe to do so.
We prioritized rollbacks on our primary applications, and at 3:46pm EST this change was prepared and started applying shortly thereafter.
After the certificate change was rolled back we started experiencing a different set of problems. Our services needed to be restarted. Redeploying was the easiest and safest way to do so since we have automated tooling and processes to assist. In general, we do not allow services to be manipulated by people manually.
As services were starting to redeploy, they were not able to fully restart. It was first suspected that there were connectivity issues as we had not fully rolled back the TLS migration and a tail of services were still in-flight. After a couple minutes of reviewing metrics, logs, and traces it was determined that it was likely a thundering herd problem, which was later confirmed by metrics.
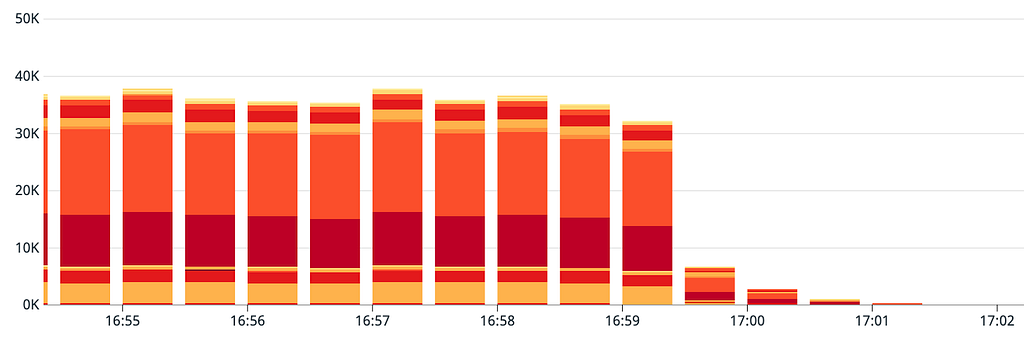
We took two actions to mitigate and at 4:48pm EST:
- We temporarily killed connectivity, effectively blocking all traffic to one of our core backend services and enabling it to sufficiently redeploy.
- We increased the number of machines for this service so that when we did re-enable traffic it would be able to handle the increased load.
By 4:59pm EST we were able to have this critical service back online and were able to reassess any remaining errors. Errors immediately dropped-off, and by 5:04pm EST nearly every service had recovered.
Root Cause
tl;dr: One of the hundreds of certificates updated was on an external load balancer where it should not have been applied. This resulted in certificate validation issues (services were not expecting this certificate) and a series of service connectivity interruptions.
We utilize both service-based load balancers and AWS load balancers. Both types of load balancers use AWS’s ACM service to provision certificates for internal applications.
The process up to this point involved updating our infrastructure codification (in our Terraform transpiler) and testing a number of web properties that went through the migration process. All of these up to this point were successful.
A PR was prepared for each group of services so that they could be reviewed and they appeared as hundreds of lines of additions of the same certificate reference that we planned and expected.

Our automated tooling that listens to webhooks ran each PR through an automated set of tests and validations. This includes running a Terraform plan on the change and producing output to review.
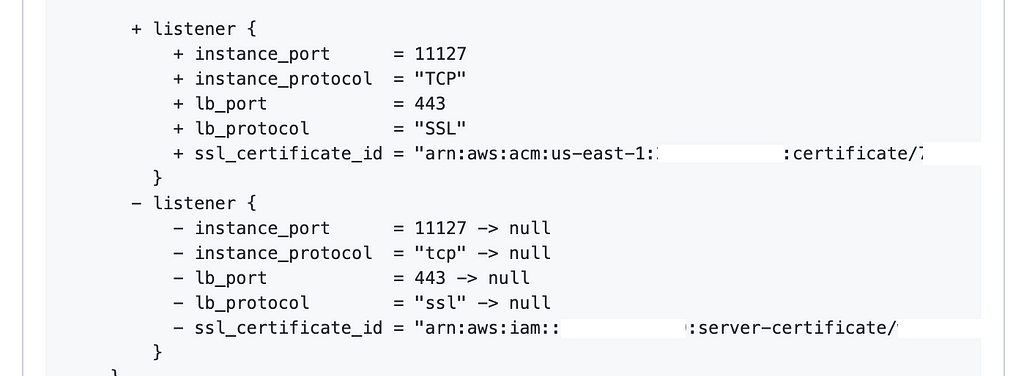
In one of the many PRs, there was a human-created mistake: one line was added to an external load balancer which should have been skipped. As previously mentioned, this was for internal certificates.
This was not easily identified, as the change itself was syntactically correct and Terraform plan correct.
All of our external load balancers are also accompanied by an additional property that we name external. If this is set, it enables traffic from our edge into the load balancer. In the case of this change, this property was correctly set but the Git diff didn’t make it clear that it was set as it was not visible. This is in-part due to the way that GitHub shows 3 lines prior and post to the changed line in the Web interface.
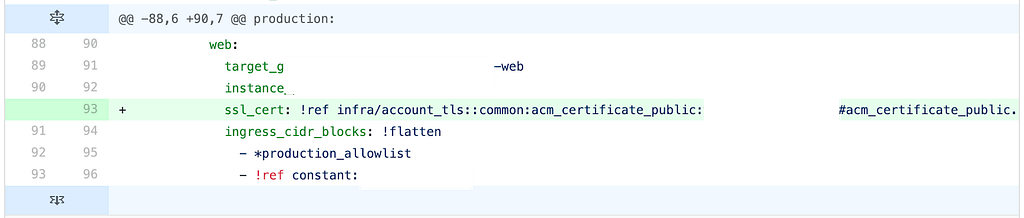
A reviewer would have had to expand the surrounding area to understand more context on this specific change and confirm that it wasn’t an external load balancer and was indeed internal.
When this change was merged, it was discovered that this particular load balancer was an external load balancer and should not have had this particular certificate rotation applied. This caused downstream services to be unable to validate the expected certificate as they were expecting a completely different certificate chain. This prevented services from being able to properly connect and serve traffic.
Looking Ahead
In response to these events, we’re working on a number of improvements. We have already written code to scan our over 700 load balancers for any mismatches between infrastructure codification and running configuration. We are actively re-testing the rollout with an increased focus on reviews for PRs where this could occur. We have automated the configuration change PRs and this automatically filters out any external load balancers preventing this from occurring.
After we hold a formal set of post mortems over the coming days we will likely identify and discuss many short and longer-term efforts to prevent this and related conditions that we learned about through this incident such as the thundering herd problem that we had not experienced before with this particular service.
We are committed to making Coinbase the easiest and most trusted place to buy, sell, and manage your cryptocurrency. If you’re interested in working on challenging availability problems and building the future of the cryptoeconomy, come join us!
This website contains links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
All images provided herein are by Coinbase.
Incident Postmortem: November 16th, 2020 was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.