
Bootstrapping the Coinbase Monorepo
How Coinbase is using a monorepo to provide developers with world-class tooling, security, and reliability

By Luke Demi
Over the past year, the developer productivity team at Coinbase has been focused on delivering a Bazel monorepo to enable engineers to more easily collaborate across the company and position the company on industry standard tooling.
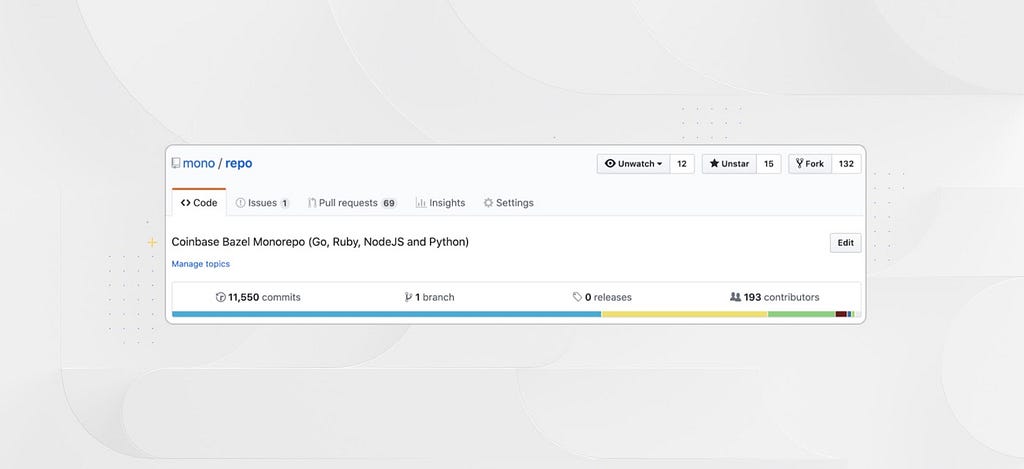
Today, our Bazel monorepo is home to over 100 projects and 22% of Coinbase’s daily deployments across four different languages (Go, Ruby, Node, Python). Our long term goal is to migrate all of the projects within the company to the monorepo. Our current trajectory has us accomplishing this goal by early 2021.
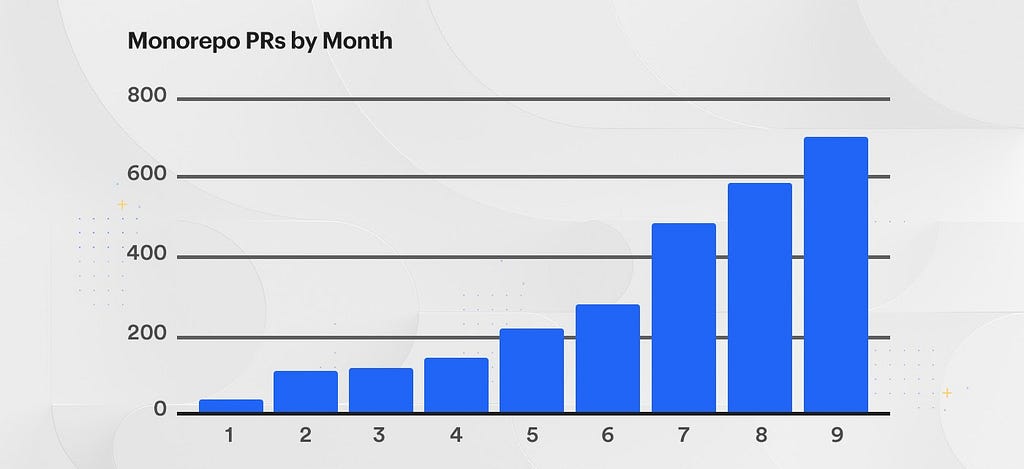
The purpose of this writeup is to:
- Outline our decision making process for choosing to go down the path of monorepo
- Describe some of the generic challenges faced by monorepos
- Describe some of the specific challenges we faced
- Extrapolate on our trajectory
Why monorepo?
Why did Coinbase choose to put a pause on our existing developer productivity tooling and head down the contentious path of monorepo?
Dependency Management
The first major reason was to solve our story around dependency management and code sharing in general. Like many other companies with many smaller services — we frequently create libraries which are shared across many (or all!) services in the company. As we’ve grown, more and more of these types of libraries (think: logging, server boilerplate, authn/authz) have been created and depended on by the nearly thousands of services in our ecosystem.
These code sharing relationships can frequently become complicated, with services depending on other services and libraries depending on other libraries. In a polyrepo world, these relationships are further complicated by the need to version and publish internal services.
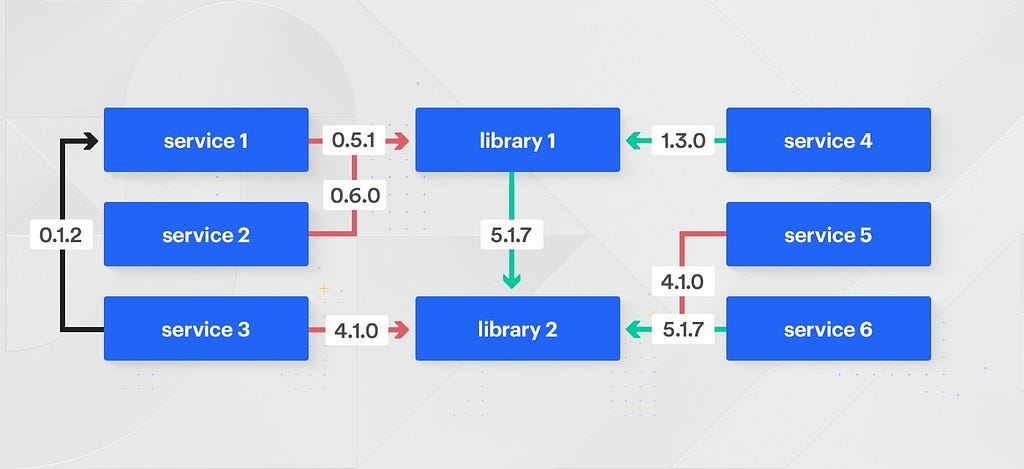
As the number of service-to-service to library-to-library relationships grow within a company, so does the need for sophisticated tooling to ensure libraries are up to date and working across the company. Adding an improvement to a critical library could take months to roll out across all of the services within an organization. There’s an accountability gap between the team making the library change and the customer teams who later apprehensively bump their versions.
A monorepo solves these versioning and publishing issues by simply removing the concepts entirely.
By definition, in a monorepo, there is only ever a single version of a given library in the codebase. Any changes made to that library are immediately rolled out to the entire company, and their impact is seen by the result of the monorepo’s test suite after the change.
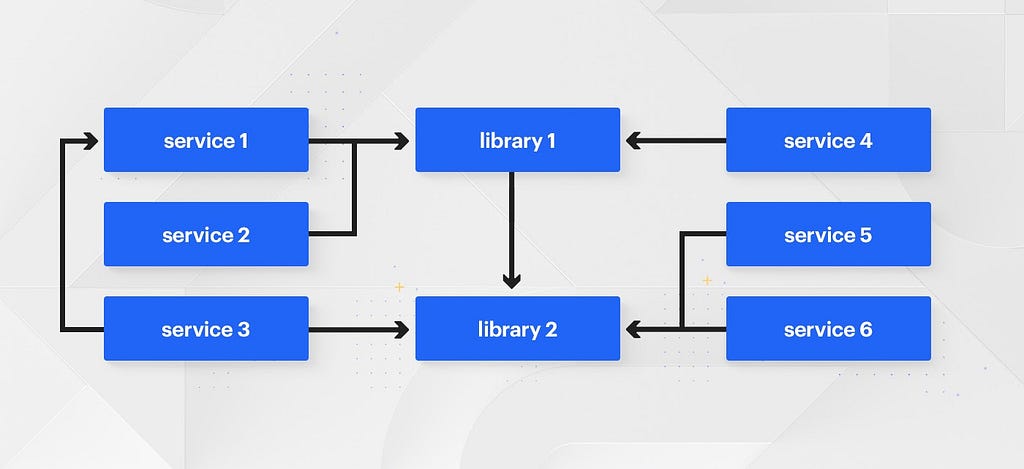
Additionally, there is no longer the need for sophisticated tooling to manage publishing, importing, and version bumping libraries. Instead, because all code lives together in a single repository, there’s never a need to publish packages to another location. If you want to rely on code written by another team, it’s as easy as importing it into your service. If you want to write a new shared library it’s as easy as writing the code in /shared and depending on it from your service.
As a result of this new workflow, changes made to widely-depended libraries will immediately trigger test suites for any dependent services. After these tests are run, the library owner can feel confident that their change has been made safely to all downstream services without manually testing those services by version bumping or waiting potentially weeks for service owners to update and find incompatibilities.
Industry Standard Tooling
The second major reason for moving forward with the monorepo is our desire to position the company on industry standard tooling.
Our existing tooling at Coinbase relies on internal, proprietary tooling to define the relationship between code and configuration. Developers use a Dockerfile to define the relationship between the code in their repository and the resulting (to be deployed) Docker image(s). These Docker images are then mapped to a docker-compose-like file that maps configuration to the generated Docker images. Finally, a tool called Codeflow handles building and mapping the relationship between these Docker images and their associated configuration before sending off a “release” to our deployment pipelines.
Our challenge with this current strategy is that Codeflow was initially designed with the strong assumption that a single GitHub repository equals a single Docker image equals a single “deployment” per AWS account.
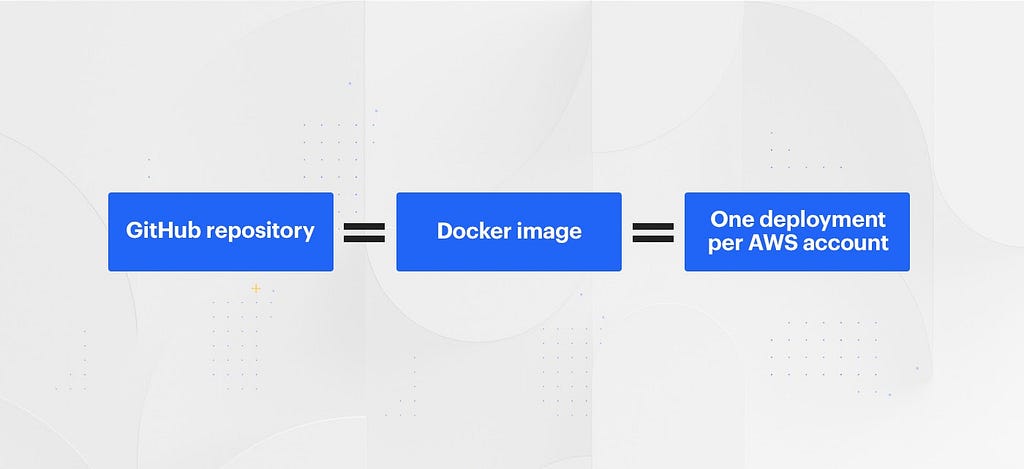
Over time, we’ve expanded (bolted on) Codeflow features to allow multiple Docker images per repository and multiple “configurations” per AWS account. However the end result of these bolt-on improvements was a stiff, proprietary, opaque chain that ties these Github repositories to their resulting multiple Docker images, then further ties them to the multiple “cloud” configurations for each of the AWS accounts (“environments”) which they are deployed.
Even at the end of all this work, engineers still desired the ability to better customize the chain from source code to “release” (Docker images + cloud metadata). Every new Codeflow feature led to an even steeper learning curve for engineers to understand these proprietary relationships.
What we needed was a way to explicitly and flexibility define the relationship between code and the resulting deployable images and metadata.
Bazel provides the building blocks required to give developers unlimited customization and visibility into the ways that their code is deployed. Rather than pre-defining opaque or stiff relationships between source code and a “release”, a typical chain of Bazel “rules” from source code to a deployable “release” might look something like this:
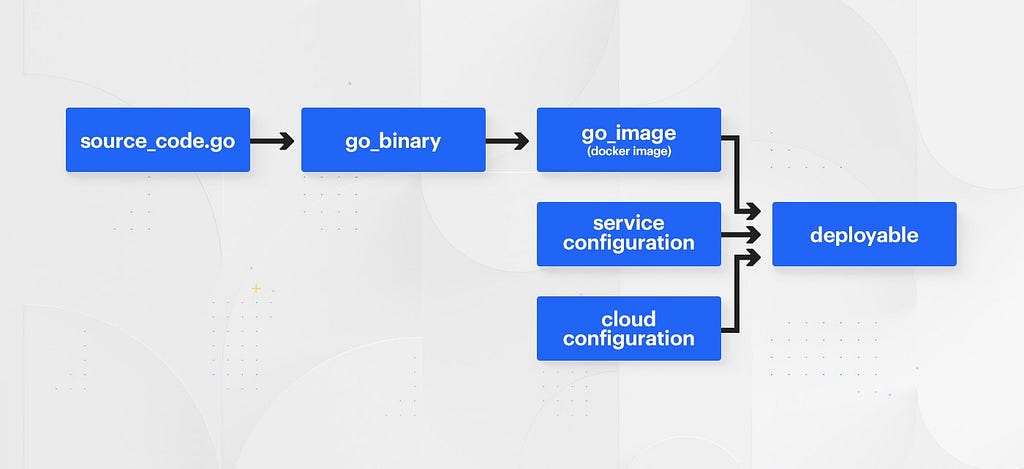
Developers are now given the flexibility to deploy their code with whatever configuration they see fit. The process by which we construct these relationships is now flexible and transparent.
We are investing in monorepo tooling because it allows us to seamlessly share code and more quickly roll out library and security changes across the organization. Additionally, it positions ourselves on industry standard tooling that more clearly defines the relationship between code and what is deployed to our cloud environments.
Generic Monorepo Challenges
Migrating all of your code into a monorepo leads to one obvious and glaring problem: the majority of the tooling released over the past decade has been designed with the assumption that one “git repository” == “one suite of tests” == “a discrete set of built artifacts”. Based on that assumption, in a polyrepo world, any time a change is pushed to a git repository, all builds and tests for that repository are run in continuous integration (CI).
However, in a monorepo, all of an organization’s services and libraries live within the same repository. Based on the above assumption, every commit to the monorepo would require testing every single test and building every single build.
Therein lies a core challenge of operating a monorepo: it no longer makes sense to fully test and build the entire repository on each commit.
Instead, we must rely on tooling like Bazel to organize all services and libraries into an explicit “build dependency graph” that we can leverage to build and test exactly what is required on each commit.
Even with tooling like Bazel to build a dependency graph of Rules (“building blocks”) within a repository, there are inevitably a significant number of Rules/libraries/services that all other libraries and services depend on within the monorepo. So simply cloning down the repository and running the tests or building the outputs of a single project could still require an hour to build.
Getting around this problem in order to bring build and test times to a reasonable level requires that builds be hermetic so that build outputs can be aggressively cached. In the context of a monorepo, “hermetic” means that a build can produce deterministic outputs regardless of which system or time of the day the build is run.

The goal of a deterministic, hermetic build output is that the output of each build can be cached and leveraged for all builds across the company they are produced in CI or a developer’s machine.
The reality is that multiple challenges stand in the way of a truly reproducible, hermetic build. For one, a hermetic build cannot use any part of the host system’s configuration because even just a small change to a system library or OS version across build hosts could result in a complete drop off in cache hit rate. Additionally, every required dependency must either be SHA pinned or have their source code included within the monorepo.
There’s no end to the number of small external influences that can play into the purity of a monorepo’s hermeticity. However, reaching “hermetic enough” to where the majority of builds produce the same outputs can dramatically improve the cache hit rate across build machines and significantly cut build times.
After building a story around caching, we adapted our existing tooling to fetch and update caches between builds to keep build times lower.
Even with a cache, the tooling required to leverage a Bazel monorepo on tooling that was designed with the “git repository” == “one collection of builds/tests” mindset can be frustrating especially as we attempt to present test results for many projects or libraries all within the space designed for single projects.
Monorepo Challenges at Coinbase
At Coinbase, many of the security controls designed to protect sensitive projects are based on the assumption that a single Github repository == a single project and enforced at the Github repository level. Placing every project (along the infrastructure tooling to deploy themselves) within a single repository would then require “one size fits all” security — effectively policing everyone within the monorepo at the level of the most sensitive project in the repository.
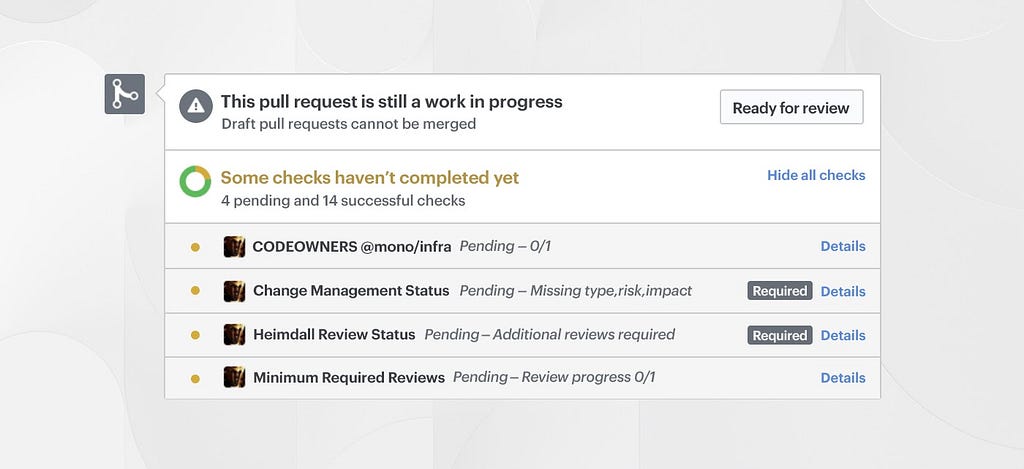
At Coinbase, we require consensus (in the form of +1s) for code to be merged to master and deployed to production. The gatekeeper to enforce this behavior is Heimdall — a service we built to keep track of +1s for any given Git commit SHA for a specific Github repository.
Our solution to solve the “one size fits all” security problem in the monorepo was to adapt our internal tool Heimdall to leverage a Github feature called CODEOWNERS. This feature lets you define the individuals or teams that are required to review code through a single CODEOWNERS file at the root of the repository with a special format of `/directory-name @github/team-name`
In our monorepo, we generate the CODEOWNERS file with a script that rolls up the content of OWNER files that live at the root of every directory in the repository. Each OWNERS file simply contains a space separated list of teams whose reviews should be required for a given directory.
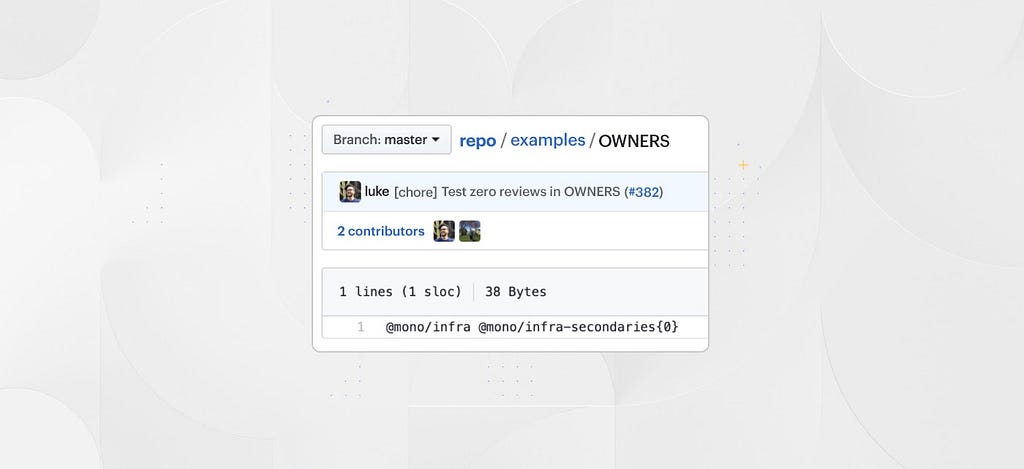
We allow for a special syntax next to teams in OWNERS files to signify the total number of reviews required by a specific team so that we can require multiple reviews for certain directories. In the screenshot above you can see the {0} indicating that zero reviews are required for a team, while {2} would require two reviews from that team. Teams without {} syntax are assumed to require one review.
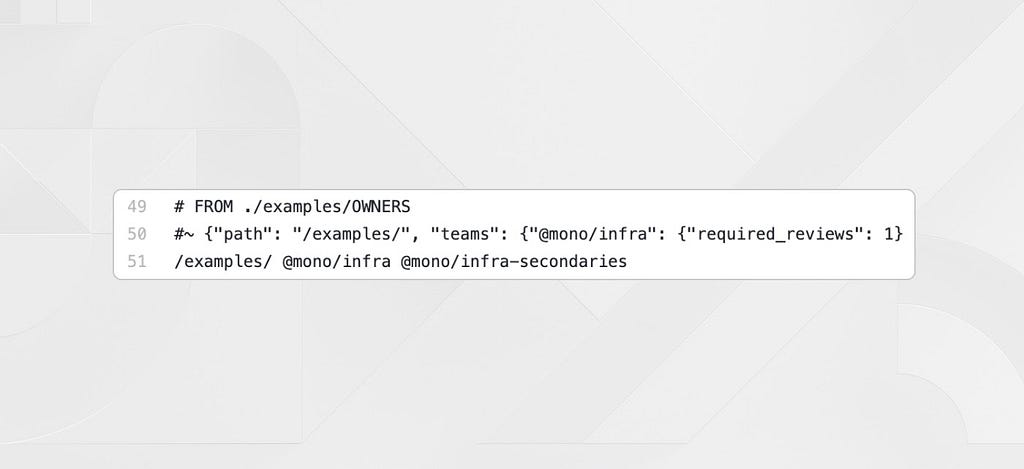
Heimdall parses all of this information with a special syntax in the CODEOWNERS file to ensure that total required reviews are met before a commit can be successfully deployed. While Github will mark a commit as reviewed with just one team approval, we have separate Heimdall GitHub statuses to ensure PRs aren’t accidentally merged without enough commits from the owning teams.
What’s Next?
Our infrastructure team’s goal is to provide developers at Coinbase with world-class tooling, security, and reliability.
While we’ve made great strides towards providing the base layer for the future of world-class tooling, there are still gaps that we need to fill before we can roll the monorepo out to the entire company.
Currently, developers use their own laptops to build and test locally. Unfortunately this means we are unable to leverage the shared caches that we populate in our build and test fleets, leading to long and potentially frustrating local build times (and loud fans!). Our solution is to provide every developer with their own remote Linux machine in EC2 so that they can easily sync up their changes to build and test quickly by leveraging shared caches.
While we’ve added support for all of the major backend languages across Coinbase, our monorepo (and Bazel itself) does not yet have strong support for client teams leveraging React and React Native. We will be working hard to add support for these frontend languages over the balance of the year.
Finally, while our current build and test tooling has scaled to ~100 projects, we expect the monorepo to expand in projects and lines of code by over an order of magnitude during the next year. We expect that this growth will cause us to run up against scaling limitations in our current caching, version control, and build strategies.
Overall, that’s the high level overview of the promise, challenges, and future of the Coinbase monorepo — expect more blog posts discussing in-depth components of our monorepo over the coming months.
If you are interested in solving complex technical challenges like this, Coinbase is hiring.
This website contains links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
Unless otherwise noted, all images provided herein are by Coinbase.
Bootstrapping the Coinbase Monorepo was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.